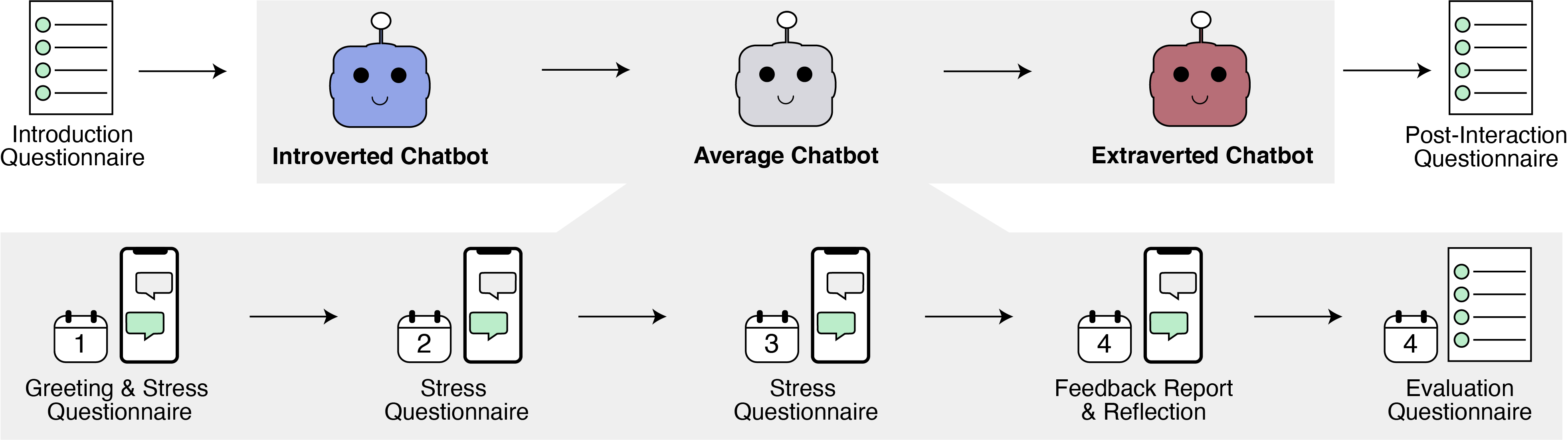
Chatbot Implementation
We developed the chatbots for the instant messaging application Telegram to support a platform-independent solution integrated in a messenger app that participants are familiar with. The chatbots were implemented in Python using the python-telegram-bot package (Link), version 12.5, and the Telegram Bot API (Link). The chatbot ran on university servers. The implementation is based on the Experience Sampling chatbot we developed in [Draxler et al. 2022].
Source Code
The source is published in this respository on Github. Please note that the current version of the chatbot implementation was intended for internal use only. We publish our source code to make the research accessible and transparent in the spirit of Open Science. That is, the source code is not documented in such a way that it can be easily reused. Whilst we intend to release a version in the future which will allow researchers to easily create their own experience sampling chatbots, this is not currently the case.
Telegram Chatbot
In Telegram, bots appear just like users but are controlled by their developers via the secure HTTPS Bot API. That is, users can simply find the chatbot in the Telegram app by using its name and start the interaction immediately.
Conversation Management
The dialogue between the user and the chatbots is determined by the conversation flow, as described above and in the paper. To minimise usability issues due to insufficient natural language understanding whilst controlling the chatbots' responses in line with their pre-defined personalities, we opted for a strictly ruled-based chatbot. The conversation flow is implemented as different states, e.g. ASKING whilst the user answers the daily DISE questionnaire.
Based on this state, the chatbots retrieve their respective responses. These responses as well as all other text elements are stored in JSON dictionaries (find the specific text modules here). Whilst in an actual application different text modules should be provided to ensure a more variied experience, for the purpose of this limited study, we only provide one version. We decided on this one version to avoid confounding effects and as most users are unlikely to always experience the same stressors each day.
The chatbots communicate with the user either via messages (do not require an answer) and questions (require an answer). We integrated different question types as described below. As several questions sound similar, we employed markup language to highlight important aspects of a message or question.
Question Types
A daily routine dynamically loads the DISE questionnaire into the chatbot program. This dynamic routine allows to modify questionnaires during runtime to allow for a more dynamic questionnaire setup in other studies. Each questionnaire comprises answer, question, and questionnaire objects. The text message as well as additional information for each question, answer, and questionnaire are stored in JSON dictionaries and converted using the Python library jsonpickle (Link).
The DISE questionnaire is translated into different message types as provided by the Telegram python-telegram-bot package. More specifically, we implemented three different question types: (1) closed single-choice questions, (2) open free-text questions, and (3) prompts to external questionnaire. To allow for branching in the questionnaire (e.g. based on whether the user had experienced a stressor or not), the user's selected or typed-in answer is compared against the pre-defined answers in the JSON dictionaries, which specifies the follow-up question based on the user's input.
Single-choice questions were realised using inline keyboard buttons. That is, the user selects one of the pre-defined answers by touching on the respective button. This type of question was for example used for yes-no questions (stem questions) as well as Likert scale questions (severity of the stressful event question and primary appraisal questions).
For open free-text questions, the chatbots send users a text message and expects a simple text string as the user's response in return. This type of question was for example used for the probe questions.
After interacting with a chatbot for three days, the users were asked to complete an evaluation questionnaire as well as a post-interaction questionnaire at the end of the study. To separate this evaluation from the chatbot experience, the users are referred to an external questionnaire hosted on the Sosci Survey platform. To this end, the chatbots send the user a link with the corresponding survey link. In this survey, the user is asked to enter their personal survey ID to match their survey data with the chatbot logging data. At the end of the survey, the user receives a code that they have to enter in the chatbot application to show that they completed the survey and may continue with the conversation.
Push Notifications
We adopted an experience sampling approach to eliminate effects due to the time of the day, e.g. users might not have experienced any stressors in the morning, or are always stressed directly after work. For the implementation, we collected the time frame during which the user is comfortable with receiving the chatbots' messages during the onboarding process at the beginning of the conversation. Every morning as part of the daily routine (cf. above), the chatbot program generates a random time within this time frame and sends a first push notification to the user to complete the DISE questionnaire at this time. If the user does not answer within two hours, the chatbots send a notification with a reminder.
Error Handling
As mentioned before, the chatbots are implemented in a strictly rule-based way to ensure consistency in the personality expressions. Hence, they cannot cope with unexpected messages. If the chatbots receive a user input they cannot recognise, they react with an error message in line with their personality. Furthermore, if the chatbot detects an error, an error message is automatically sent to the developers' Telegram group chat. One such error occurred during the study, allowing the developers to fix the problem within thirty minutes without loosing any user data.
Database
We saved the user's information (e.g. preferred time frame) and all of their answers to the questionnaires in a MongoDB database (Link). On the one hand, the database serves for logging and analysing the data. On the other hand, the database provides a persistent storage of the user's information that the chatbots can access, for example to create the feedback report (cf. below). To this end, we used the Python driver PyMongo (Link). As the users described very personal stories about their daily stressors including first names of other involved people, we do not publish their answers. However, interested readers are invited to contact the first author in case of questions.
In addition to the database, we used the Telegram bot's pickle PicklePersistence to save the user's current state in the conversation flow (e.g. finished day 2). This persistent storage allows us to ensure that each individual user completes all parts with each personality-imbued chatbot in the intended order.
The Figure below shows the entity-relationship diagram for our database.
User Feedback Report
The feedback report comprises four components: (1) a bar chart with the number of stressors the user experienced, (2) a line chart visualising the severity of the experienced stressors, (3) a line chart illustrating the user's mood each day, as calculated through a sentiment analysis performed on the users' answers to the open-ended questions, and (4) a short explanation of the charts. Below, the implementation of the charts as well as the calculations of the stressors, severity of them, and the users' mood are briefly explained.
Feedback Charts
We automatically generated bar and lines charts to illustrate participants' stressors using the Python library Pygal (Link). To this end, the chatbots retrieve the information about the user's stressors from the database and calculate the respective information as describes below. The Pygal library then creates the charts on-the-fly and saves them as PNG-files in a chosen directory of the chatbot program. The chatbots can access the files and send them to the user.
In addition to the charts, the extraverted chatbot sends a smiley illustrating the user's mood. To this end, we designed three mood smileys (happy, neutral, sad) and then created all possible mood figure combinations. That is, the user's mood state (happy, neutral, sad) is collected on three days resulting in 3³ possible combinations. Based on the calculated mood (see below), the extraverted chatbot selects the correct figure and sends it to the user.
Stressor Calculation
Number of Stressors: As described in the paper, the chatbots collect a user's daily stressors by going through the DISE questionnaire. This questionnaire features seven yes-no stem questions. The number of stressors the user has experienced each day is calculated by the sum of the stem questions the user has answered in the affirmative:
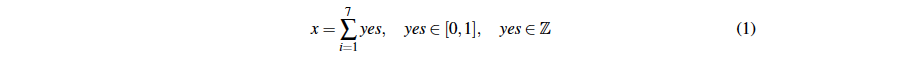 The daily number of stressors are displayed as a bar chart as described above.
The daily number of stressors are displayed as a bar chart as described above.
Severity of the Experienced Stressors: For each affirmative stem question, the chatbots ask the user a Likert scale question about how stressful the event has been for them. If the user selects the answer option Not at all stressful, this stressor is not considered further. If the user selects any of the other three answer options (A little stressful, Somewhat stressful, Very stressful), the user is prompted with seven additional primary appraisal questions pertaining the user's stressor. Again, each of these questions has four answer options representing four severity scores k (one as the lowest, four as highest score).
Based on these seven questions, a severity score between one (not severe) and four (very severe) is calculated for the user's daily stressors by averaging the single severity scores over the seven primary appraisal questions and the number of affirmative stressors (as gathered through the stem questions):
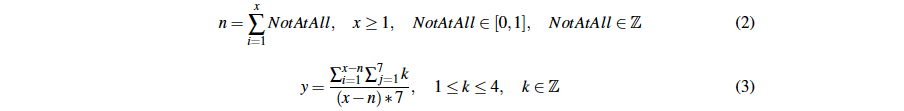 The daily severity scores are displayed as a line chart as described above.
The daily severity scores are displayed as a line chart as described above.
Sentiment Analysis
For each affirmative stem question, the chatbots prompt the user with (partly different) open-ended probe questions that collect the participant's description of the stressful event. To present the user with information about their daily mood, the chatbots perform a sentiment analysis on the users' free-text answers to these probe questions. We conducted the sentiment analysis using the Python Natural Language Toolkit (NLTK) VADER [Hutto et al. 2014], which employs a simple lexicon-based sentiment model. The VADER model returns four values, the positive, negative, neutral, and compound sentiment score. In this project, we use the compound score which is calculated from the three individual scores and ranges from -1 (negative) to 1 (positive), indicating the overall strength of the sentiment.
To determine the user's daily mood, we concatenated all answered probe questions for all affirmative stem questions into a single string. We did this as some of the open-ended questions require only brief answers and the sentiment scores are more meaningful for longer texts. Then, we conducted the VADER sentiment analysis as described above on the concatenated string to obtain the user's overall sentiment of the day. The chatbots interpret a score greater than or equal to 0.05 as positive, a score smaller or equal to -0.05 as negative, and a score between those two values as neutral. The daily sentiment scores are displayed as a line chart as described above and a smiley in case of the extraverted chatbot.